Agentic Testing vs Playwright: Lessons from QA.tech
I’ve talked to a lot of people who claim their tool does “agentic testing.” Most of the time it’s a Playwright wrapper with a marketing team that discovered the word “agent.”
Vilhelm von Ehrenheim is different.
Before founding QA.tech, he spent years at EQT building Motherbrain, one of the earlier production LLM systems in venture capital, making decisions on real deal flow before most people had heard of GPT. Before that he was building real-time fraud detection models at Klarna at 300,000 transactions a day. He’s shipped AI systems at scale, watched them fail, and figured out why.
All that to say Vilhelm really knows his stuff.
So when he built a testing company, I wanted to know: what does someone with that background see in this space that the rest of us are missing?
We got into it in Episode 590 of the TestGuild Automation Podcast.
Here’s what stood out, plus what I think it means for the engineers actually doing this work.
Quick note on transparency: this conversation was sponsored by QA.tech, which means they supported the episode (590) I interviewed them for. The analysis and takes below are mine. I don’t cover tools I don’t think are worth your time, and I’ll tell you where I think the honest limits are.
What Is Agentic Testing?
Before we get into QA.tech, let’s make sure we’re all on the same page. ‘Agentic testing’ gets used a lot these days, so how do you define it?
Agentic testing is an approach where AI agents autonomously explore, validate, and reason about application behavior rather than executing fixed, locator-based scripts. The agent has a goal, “verify that a logged-in user can complete checkout with a discount code”, and it figures out how to pursue that goal based on what it perceives in the application, updating its understanding as it goes.
A lot of people lump those together, but they’re actually very different.
- Scripted automation (Playwright, Selenium, Cypress): The framework replays a recorded sequence. It verifies that a specific click at a specific element produced a specific result. Brittle by design.
- AI-assisted script writing: An LLM helps you write or repair scripts faster. Still scripted underneath. Still brittle. Just cheaper to author.
Only the third thing, the actual perception-action loop, is agentic testing. Most tools marketing themselves as agentic are really in category two.
For a concrete example of that third category rather than the second: QA.tech is an agentic testing platform built around an actual perception-action loop. The agent perceives the app, decides, acts, and updates as it goes, instead of replaying a recorded sequence.
Try QA.tech’s Agentic Testing Platform
Why AI-Assisted Development Creates New QA Bottlenecks
The first thing Vilhelm said made me stop and think.
His team put out a field guide on bottlenecks in AI-assisted development, and the core observation as this: AI coding tools didn’t solve the software delivery problem, they moved it.
You write code faster, but everything downstream, review, testing, deployment confidence, gets hit harder.
As Vilhelm put it: “When you make one part faster, you naturally just shift the bottleneck by the old theory of constraints.”
I’ve been saying something similar for years under what I call the Jevons Paradox of Testing: more AI means more testing demand, not less. In my State of Automation Survey data, AI adoption in testing teams went from 2% in 2018 to over 72% in 2025. The teams that are thriving aren’t the ones who cut their QA investment, they’re the ones who changed what QA does.
Vilhelm’s observation matches what I’ve heard across 590+ automation testing podcast interviews with practitioners: the teams handling AI-accelerated development best are either very lean or heavily automated. If your QA process lives in someone’s head, faster coding just creates faster chaos.
The constraint moved from writing code to verifying it. That’s the whole problem QA.tech is trying to solve.
How QA.tech’s Behavioral Knowledge Graph Improves Agentic Testing
Most agentic testing approaches I’ve seen treat the app like a black box: point the agent at a URL and hope it figures things out. That works for about three flows. Then it falls apart.
One thing I’ve learned from the TestGuild community is that testers hate black boxes.
They want to know what’s actually happening and why.
QA.tech’s answer is a behavioral knowledge graph, and that’s what really differentiates it from “Playwright with an AI wrapper.”
Ok, so you might be asking what is a behavioral knowledge graph?
Good question.
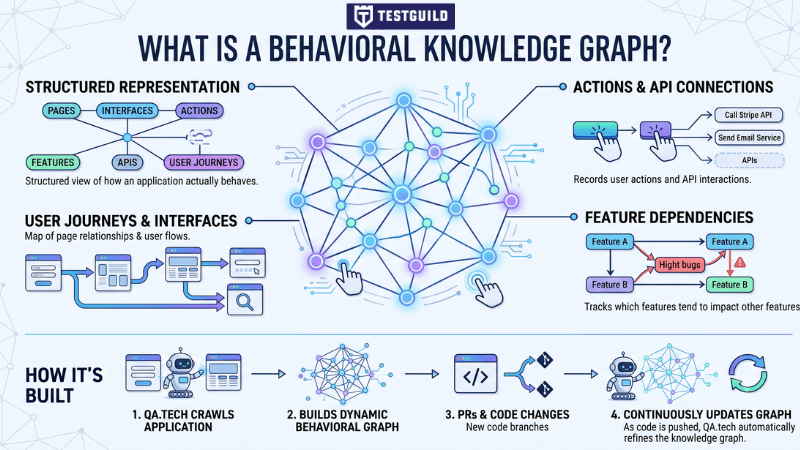
What is a behavioral knowledge graph?
A behavioral knowledge graph is a structured representation of how an application actually behaves, user journeys, interfaces, page relationships, actions, API connections, and which features tend to affect which other features. QA.tech builds this graph by crawling your application and continuously updating it as PRs come in.
Cool – right?
Here’s why it matters…
Vilhelm explained: “A deployed application is so much more than what the code typically says. If you as a manual tester are clicking around and validating that stuff is working, you typically build up your own memory about how the application functions.”
That’s exactly right.
An experienced tester two years into a product carries an enormous amount of context that never gets written down. They know which user journeys are fragile, which features break together, which edge cases the dev team always forgets. The knowledge graph is an attempt to encode that institutional memory in a form the agent can actually use.
The practical result: when a change comes in, the agent already knows what it might affect. It doesn’t start from zero every time.
Create a Behavioral Knowledge Graph For your App Now
Agentic Testing vs Playwright and Claude Code
Playing devil’s advocate, I had to ask since most testers are skeptics at heart: why not just wire up Playwright with an LLM? Lots of teams are doing exactly that, and it’s basically free.
Vilhelm’s answer was honest:
“I think the risk of doing it with Claude without being very specific and mindful about what you’re doing is that you’re just going to have a lot of code. It’s going to be much harder to actually have a clear understanding and intent with all the stuff that you have done.”
Here’s the structural problem with “Playwright plus a model.” The approach works fine for three to five flows. Then:
- The context window fills up and the agent loses track of what it already discovered
- Coverage fragments into isolated experiments instead of a coherent model
- You end up with hundreds of generated tests and no confidence about which ones are testing the right things
I’ve seen this exact pattern play out.
Teams generate a ton of Playwright tests with AI assistance and end up with something harder to maintain than what they had before.
I’ve said this for years: volume of tests is not the same as confidence in quality.
The infrastructure that makes agentic testing actually scale,persistent memory, hierarchical context, multi-agent orchestration, and evaluation harnesses for every agent decision, is also the part most people never see. It’s not a flashy demo. It’s the engineering underneath the demo.
This is one area I think teams consistently underestimate.
Building it yourself is a multi-year engineering commitment to a problem that isn’t your core business.
That’s one of the strongest arguments for a purpose-built system versus a DIY stack. Most testing teams want to spend their time improving quality and shipping software, not building and maintaining AI infrastructure.
Next, I want to cover the difference between traditional automation, AI-assisted testing, and agentic testing, because most testers I speak with are still a little fuzzy on where the lines are.
Traditional Automation vs AI-Assisted vs Agentic Testing: A Comparison
Here’s how the three approaches actually stack up. I’m including the tradeoffs because any comparison table that has one approach winning every row isn’t giving you the full picture.
| Approach | Traditional Automation | AI-Assisted Scripting | Agentic Testing |
|---|---|---|---|
| Best for | Stable, repeatable flows that rarely change | Faster creation and repair of existing scripts | User-facing journey validation where intent matters most |
| Main strength | Deterministic, debuggable, auditable | Speeds up an existing automation practice | Adapts to UI and flow changes without script rewrites |
| Main weakness | Brittle when UI changes; high maintenance drag | Can generate high test volume without improving confidence | Needs app context, calibration time, and an eval strategy |
| Human role | Author and maintain scripts | Review and approve generated scripts | Define strategy, intent, risk thresholds, and evals |
| Setup reality | High upfront investment in script authoring | Medium, you still need an automation foundation | Lower technical setup, but strategy setup still matters |
| Results type | Deterministic pass/fail | Deterministic pass/fail | Probabilistic, requires human review of findings |
| Good fit when | You need precise, repeatable checks on stable flows | You already have an automation stack and want to move faster | Your app changes frequently and locator-based tests keep breaking |
| Be careful when | Dev velocity outpaces your ability to maintain scripts | You need genuine coverage confidence, not just more tests | You need fully deterministic audit-style verification |
That left-to-right distinction is the one most teams haven’t internalized yet, so it’s worth being concrete about what actually sits in the “Agentic Testing” column.
QA.tech is the clearest example I’d point to: an agentic testing platform that validates intent against a behavioral knowledge graph, rather than running script-based regression with a model bolted on top. That architecture is exactly why it lands in a different column than Playwright or AI-assisted scripting, and if you want the row-by-row version of agentic QA versus a script-based framework, they run the same exercise in more depth in their Playwright comparison.
The key row is “results type.” Agentic testing produces probabilistic results, which means someone still needs to review findings and decide what to act on.
That’s not a knock on the approach, it’s just the honest reality of how it works right now.
Validating Intent, Not Clicks
This was probably my favorite part of the entire conversation.
I was pushing Vilhelm on what a test case actually looks like in QA.tech, do you write code?
Do you write scripts? He said no, there’s no code. You define tests at a higher level, focused on what should be achievable in the product, not how to get there.
I said: “So rather than verifying clicks, you’re validating intent?”
He said: “Yes. Exactly. Because that’s what we really care about. You don’t necessarily care about the specific clicks on the identifiers, you care much more about the actual user intent and experience.”
This is a genuinely different mental model from traditional automation.
Selenium, Playwright, Cypress, all built around locators and sequences. You tell the tool exactly what to click, in what order, with what timing. That’s why tests are brittle. The app changes, your locators break.
I’ve heard versions of this distinction from some of the people who built the tools themselves. Simon Stewart, one of the WebDriver creators, has talked about how the original goal was always to test behavior, not implementation, but the tooling ended up pushing practitioners toward the implementation layer because that was easier to automate.
What QA.tech is building is closer to the original intent.
Testing intent instead of implementation is harder to define upfront. It’s much less fragile over time.
Why “Adaptive Testing” and Not “Self-Healing”
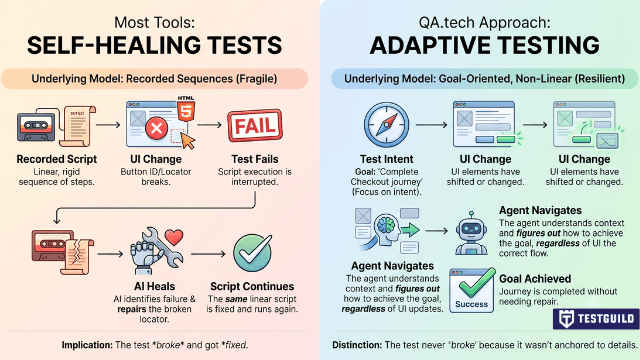
Most tools that handle UI changes call it “self-healing.” QA.tech doesn’t use that term, and the distinction is worth understanding.
Self-healing implies the test broke and got fixed. The underlying model is still: you have a script, the script failed, the AI repaired the locator. You’re still in the world of recorded sequences.
Adaptive testing means the agent never had a rigid locator to break in the first place. It’s testing the intent, can this user complete this journey?, and it navigates to accomplish that goal regardless of what changed in the UI. The test didn’t need to heal because it wasn’t anchored to implementation details that could break.
That’s not just a branding difference. It’s a different architecture with different failure modes.
What Agentic Testing Means for QA Engineers Right Now
This is the part I know people actually want to know, so I’m going to be direct about it.
The QA engineer role isn’t going away.
What’s going away is the specific work of manually executing scripted test cases at scale and maintaining Selenium suites through every UI redesign. That work is getting absorbed by tools like QA.tech, and that’s honestly not a tragedy, it was never where the best QA people were spending their best thinking.
What gets more important:
Quality strategy. Knowing which user journeys actually matter for your specific product. No agent figures that out for you. You have to tell it.
Evaluation. As Vilhelm put it, and this comes from his background in credit risk modeling where automated decisions had real money on the line: “Of course people don’t trust it from the start. You need to prove yourself. You need to make sure and validate that the models are actually performing up to par on what is required.” Someone has to assess whether the agent is testing the right things. That’s a human judgment.
Risk thinking. Which failures are catastrophic versus cosmetic? An agent can find a lot of issues. You still need someone deciding which ones to act on.
AI collaboration. Working effectively with agent-based systems, understanding where they’re confident versus uncertain, knowing when to trust the output and when to dig in. This is a new skill and it’s real.
The teams I’ve watched handle this transition well are the ones who reframed their QA function from “people who execute test cases” to “people who own quality outcomes.” That shift matters more than which tool you use.
On Trusting AI Test Results
This is the real question nobody wants to answer directly. I asked it.
Vilhelm’s answer came from his risk modeling background: build evals, collect historical input/output data, make sure your AI pipeline can at least match what your manual process was doing before you trust it to replace that process.
That’s not a flashy answer. It’s the right one.
The teams seeing the best results with QA.tech are the ones who treat the first few weeks as a calibration period, running agent-based tests in parallel with existing processes, comparing results, building confidence before cutting over.
Same methodology you’d use for any high-stakes automated decision system.
Is Agentic Testing Right for Your Team?
Honest answer: it depends on where your actual pain is. Here’s how I’d think about it.
Agentic testing is a strong fit when:
- Your app changes frequently and locator-based tests are expensive to maintain
- You have preview environments available for PR-level testing
- You want to validate user journeys and product behavior, not just CSS selectors
- Your team can spend time in the first few weeks calibrating the agent and reviewing results
- Your biggest QA bottleneck is coverage breadth, not deterministic verification of a fixed set of flows
Be careful, or look elsewhere, when:
- Your critical flows require fully deterministic, audit-style verification with a clear pass/fail paper trail
- You don’t have stable test environments or working test credentials to give the agent
- Your bugs are mostly deep backend issues, data integrity problems, or intermittent race conditions, the agent won’t catch those reliably
- You’re expecting a zero-setup replacement for your entire QA process on day one
- Your team doesn’t have anyone to own quality strategy and review agent findings, the tool handles execution, not judgment
One more thing worth saying: if you’re currently running a Playwright or Selenium suite that’s working well for your specific product, agentic testing isn’t a reason to throw that away. It’s a complement for the coverage that scripted tests can’t reach, not necessarily a replacement for the parts they handle well.
Getting Started With QA.tech
Setup is lighter than you’d expect. You give it a URL and credentials. QA.tech handles the infrastructure, you don’t manage scaling or agent orchestration.
There’s an exploratory phase when you first onboard where it maps your application and builds the initial knowledge graph. After that it updates continuously as PRs come in. The GitHub integration is straightforward: install it, it listens on webhooks, and when a PR opens with a preview environment, the agent analyzes what changed and posts a review with pass/fail, screen recordings, and reproduction steps for anything that broke.
The bug reproduction use case stood out to me. Paste a user bug report and the agent tries to reproduce it. Vilhelm was honest that it depends on complexity, intermittent bugs aren’t great candidates. User-facing bugs with a clear description usually are.
His advice for getting started: “Get your hands dirty. Don’t get stuck because it didn’t work for one specific thing. Think about what needs to be there in order for it to actually have the capability and the knowledge to actually do it well.”
Good advice for AI tooling in general.
Listen to the full conversation with Vilhelm von Ehrenheim in Episode 590 of the TestGuild Automation Podcast.
Want to go deeper on agentic QA adoption? QA.tech put out a field guide called Past the Bottleneck that covers how to think about the shift and what an actual adoption playbook looks like. Worth reading before you start evaluating tools in this space.
This post was produced in partnership with QA.tech. All opinions are my own, I don’t cover tools I don’t think are worth your time.
FAQ
What is agentic testing? Agentic testing is an approach where AI agents autonomously explore, validate, and reason about application behavior rather than executing fixed, locator-based scripts. Unlike traditional automation frameworks like Playwright or Selenium, agentic testing focuses on user intent and expected outcomes, can this user complete this journey?, rather than verifying that a specific sequence of clicks produced a specific DOM result. The agent perceives the application, decides what to do, takes action, and updates its understanding based on what it observes.
What is QA.tech? QA.tech is an agentic testing platform that uses a behavioral knowledge graph to test web and mobile applications without requiring written test scripts or automation code. It maps user journeys across your application, then uses autonomous agents to verify that changes don’t break existing behavior. It integrates with GitHub, GitLab, and Azure DevOps to automatically test pull requests when preview environments are available. It works across web, mobile web, iOS, and Android.
What is a behavioral knowledge graph in testing? A behavioral knowledge graph is a structured representation of how an application actually behaves, user journeys, page relationships, available actions, API connections, and which features affect which other features. QA.tech builds this graph by crawling your application and continuously updating it as new code ships. The graph gives agents the context they need to make informed testing decisions rather than exploring from scratch on every run.
How is agentic testing different from Playwright or Selenium? Traditional automation frameworks like Playwright and Selenium execute specific sequences of locator-based actions, find this element, click it, check the result. That makes tests brittle when the UI changes. Agentic testing validates intent instead of implementation: can a user complete this journey? The agent reasons about what it’s looking at rather than following a rigid script, which makes it more resilient to UI changes and product evolution.
Why isn’t “Playwright plus Claude” a real solution for agentic testing? It works for the first few flows. Then it breaks down: the context window fills up, the agent forgets what it already discovered, coverage fragments into isolated experiments instead of a coherent model, and you end up with a large volume of generated tests with no clear signal about whether they’re testing the right things. The infrastructure that makes agentic testing actually scale, persistent memory, hierarchical context, multi-agent orchestration, evaluation harnesses, is precisely what’s invisible in a demo but essential in production. Building it yourself is a multi-year engineering project to a problem that isn’t your core business.
What is adaptive testing vs self-healing testing? Self-healing testing means a test script broke and an AI repaired the locator. The underlying model is still a recorded sequence that can fail. Adaptive testing means the agent never had a rigid locator to break in the first place, it’s testing user intent, not implementation details, so UI changes don’t require a repair. It’s a different architecture, not just a different term.
Is agentic testing ready for production use in 2026? More ready than it was. QA.tech started building when agentic AI “barely worked with GPT 3.5” by Vilhelm’s own description. The underlying models have improved significantly. That said, it’s not zero-config magic, quality of results depends heavily on the context and knowledge you give the system. Teams that invest in proper onboarding and treat the first months as a calibration period are seeing real results. Teams expecting it to work perfectly out of the box with no setup are going to be disappointed.
Will AI testing tools replace QA engineers? Not replace, reshape. The demand for people who think clearly about quality strategy, know which user journeys matter, and can evaluate whether automated results are trustworthy is higher than ever. What’s going away is purely manual execution of scripted test cases at scale. That work is getting absorbed by tools like QA.tech. The judgment work, what to test, whether results mean something, how to structure a quality pipeline, still needs people.

Joe Colantonio is the founder of TestGuild, an industry-leading platform for automation testing and software testing tools. With over 25 years of hands-on experience, he has worked with top enterprise companies, helped develop early test automation tools and frameworks, and runs the largest online automation testing conference, Automation Guild.
Joe is also the author of Automation Awesomeness: 260 Actionable Affirmations To Improve Your QA & Automation Testing Skills and the host of the TestGuild podcast, which he has released weekly since 2014, making it the longest-running podcast dedicated to automation testing. Over the years, he has interviewed top thought leaders in DevOps, AI-driven test automation, and software quality, shaping the conversation in the industry.
With a reach of over 400,000 across his YouTube channel, LinkedIn, email list, and other social channels, Joe’s insights impact thousands of testers and engineers worldwide.
He has worked with some of the top companies in software testing and automation, including Tricentis, Keysight, Applitools, and BrowserStack, as sponsors and partners, helping them connect with the right audience in the automation testing space.
Follow him on LinkedIn or check out more at TestGuild.com.
Related Posts

What is Model Context Protocol (MCP) Model Context Protocol (MCP) is an open standard that lets AI agents — Cursor, […]
Look, I’ll be straight with you. I’ve been vibe coding in Cursor for about a year and a half, and […]

Here’s the thing about API testing tools: the list has exploded. What used to be “Postman or SoapUI?” is now […]

After blogging about testing for over fifteen years, I realized something embarrassing a while back: I’d never actually sat down […]